Real-world benchmarking of cloud storage providers: Amazon S3, Google Cloud Storage, and Azure Blob Storage
Tweet
I really wouldn’t mind moving from Dropbox to S3, Google Cloud Storage, Azure Storage, or any other provider
Recently at work I’ve been using the fancy new 4K iMac, yet when I’m at home or out-and-about, I use my equivalently-sexy MacBook. I do the same stuff on both computers though, it just so happens that one is way faster and has a bigger screen, and the other is slower though portable and much more practical for my lifestyle. They both need access to the same files.
Typically to solve this problem you’d use Dropbox or a similar service. But one thing I strongly dislike about specifically Dropbox is that it really wants you to sync everything to every computer. To me this seems extremely wasteful as I might not want the storage overhead of syncing my personal photos onto my work computer. Ideally files could be uploaded to a service, but only downloaded on demand. I understand Dropbox has Selective Sync, but that’s not what I want. I should be able to mount all my stuff onto a Raspberry Pi for example.
What got me curious though is: which of the major cloud services out there actually focused on performance? I have 100mbit+ symmetric connections at both home and work (thx MonkeyBrains and Mimosa! pic here), so I figured that I should optimize for low-local-storage requirements yet be ok with high-bandwidth usage.
We’ll be testing
 Amazon AWS S3
Amazon AWS S3
 Google Cloud Storage
Google Cloud Storage
 Microsoft Windows Azure Blob Storage
Microsoft Windows Azure Blob Storage
I would have wanted to also test Backblaze’s B2 thingy, but I haven’t been invited into their Beta program yet. ;(
Testing methodologies
For all three services I want to test 3 real-world things:
- Large file: I created a 100mb file using
mkfile 100m ~/Desktop/100m. - Small files: I found a git repo on my machine and copied the
.gitdirectory. - Many instructions: After the above git directory was synced, I removed all the files from the cloud provider.
Also, the point of this is that it’ll be used from the consumer side. So this was all run on my own laptop and to the service’s storage datacenter which was closest to San Francisco, CA.
Methodology A: Mounting filesystems
-
Google Cloud Storage (gcsfuse)
gcsfuse --limit-bytes-per-sec "-1" --limit-ops-per-sec "-1" --debug_gcs lg-storage cloud time cp ~/Desktop/100m ~/cloud/100m time cp -r ~/proj/myrepo/.git/ ~/cloud/myrepogit time rm -rf ~/cloud/myrepogit -
Amazon AWS S3 (Transmit app)
For AWS I used Panic’s Transmit app to mount the disk, along with their Transmit Disk patch. I would have tried to use s3fs-fuse to mount via Fuse, but since I’m running El Capitan on my laptop, the new signed-only kext changes have completely broken my ability to use it. I used the same
cpandrmcommands as for Google Cloud Storage. -
Microsoft Windows Azure Blob Storage
No tools exist to mount this as a disk on my mac :(
Methodology B: Using their sync SDKs
Using the sync SDKs, although easier, bring the downside that we’re now syncing all files/folders, very contrary to the whole premise of this exercise. That said, it could be useful for comparisons.
-
Google Cloud Storage (gsutil)
time gsutil -m rsync -d -r ~/Desktop gs://lg-storage time gsutil -m rsync -d -r ~/proj/myrepo/.git gs://lg-storage/myrepogit time gsutil -m rsync -d -r ~/empty gs://lg-storage/myrepogit -
Amazon AWS S3 (aws-cli)
time aws s3 sync --storage-class REDUCED_REDUNDANCY --delete ~/Desktop s3://lg-storage time aws s3 sync --storage-class REDUCED_REDUNDANCY --delete ~/proj/myrepo/.git s3://lg-storage/myrepogit time aws s3 sync --storage-class REDUCED_REDUNDANCY --delete ~/empty/ s3://lg-storage/myrepogit -
Microsoft Windows Azure Blob Storage (blobxfer.py)
time blobxfer --storageaccountkey "..." lgfilestorage lgfilestorage ~/Desktop/100m time blobxfer --storageaccountkey "..." lgfilestorage lgfilestorage ~/proj/myrepo/.gitUnfortunately, blobxfer.py provides no way to delete files from Blob Storage. I’ve created an issue for this here.
The results

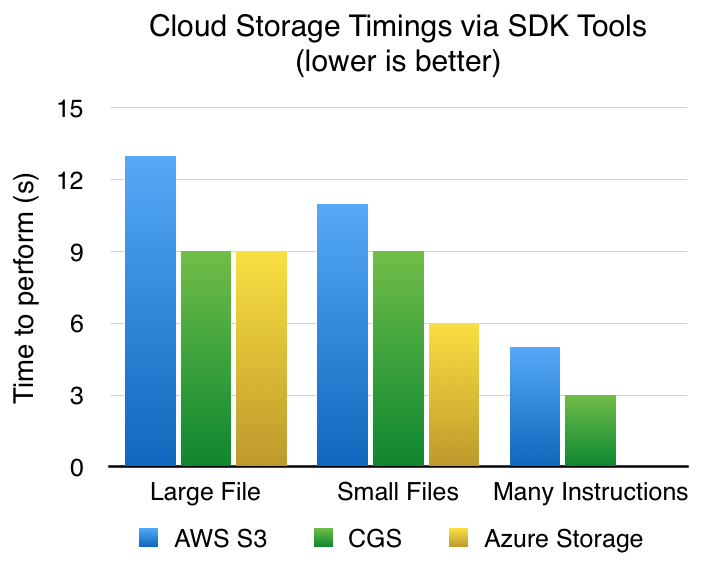
There are a variety of things to note in these results:
-
Each request to any of the services is super slow. When debugging, I noticed an average time of 100ms-300ms just to get the metadata of a file that exists there. When mounting, a lot of these
stat-like requests are done, slowing things down dramatically. Weird that the latency is so high – you’d think it should only be a few miliseconds at most. -
Using any kind of Disk Mounting is a bad idea. FWIW, I expected this, but I didn’t expect it to be that bad. I guess it makes sense though, the storage provider has no idea which files you’re going to access so it can’t parallelize anything for you. When using the sync SDK method, they usually launch tons of parallel requests since then it knows all the files in a folder that need to be transferred.
-
Azure’s tooling for non-Windows is extremely poor. Right now there’s literally one guy, Fred, who’s building out tooling for us non-Windows folks. Because of the immaturity of what’s actually available, I couldn’t run many tests, including file deletion from Azure and also any form of mounting of Azure Storage to my local filesystem. I feel like this could be really hurting Microsoft’s adoption amongst people and businesses that use real operating systems for their automations.
-
Using the services’ sync SDKs was surprisingly quite fast. They’re all on even footing (unlike the disk mounting method), with Azure being the fastest on average. It was quite noticeable actually.
Conclusion
These results aren’t good for what I originally set out to do. Yes it’s great I have a possibly-faster-than-Dropbox solution, but I don’t want to sync everything everywhere. The disk mounting method, though possible, is still extremely slow and makes it almost impractical for what I am trying to do.
Perhaps a tool that someone should build is something that uses the sync SDK method to transfer files, but something else for directory listings. When it appears that the user is touching a file in a folder (say a git repo), the tool would pull the whole repo locally in parallel. Or maybe only if you’re accessing 5+ files in a folder will it download the whole thing. I think there’s space for some sort of smart caching tool that also auto-deletes infrequently used files depending on free disk space (or a specified quota). That way what’s stored on my computer is minimal, but I still have access to everything, everywhere (assuming I have a good internet connection).
As for the data collected, when comparing the three providers, Azure seems to be the fastest, but hardest to use. Google is quite fast too, with better tooling. And AWS S3 is also quite fast, but probably with the best tooling (there’s even iOS apps to browse your S3 Buckets!).
Overall, FML, I don’t know what to do. Please email me, trivex@gmail.com, if you have ideas.